Op ontdekkingsreis door een keur aan databronnen
28 november 2024

Hoe kunnen we specifieke vakkennis, die bij onderzoekers in het hoofd zit, geschikt maken voor analyse door een computer? ‘In ons hoofd hebben wij een bepaalde manier om dingen te beschrijven of categoriseren, maar een computer begrijpt die niet. Een onderzoeker weet bijvoorbeeld hoe nieuwe diersoorten geïdentificeerd worden, en een socioloog hoe nieuwe onderzoeksvragen over onze samenleving tot stand komen, maar een computer weet dit niet.’ Een computer moet daarvoor leren om semantische verbanden te leggen, dus niet alleen maar weten welke hoofd- en subcategorieën mensen gebruiken, maar ook allerlei andere indelingen kunnen maken. Als computers toegang krijgen tot die kennis, wordt onderzoek meer reproduceerbaar, en liggen er nog vele wetenschappelijke ontdekkingen binnen bereik, denkt Stork.
Sociale geschiedenis en biodiversiteit
Kort gezegd is dat waar Lise Stork zich al een tijdje mee bezighoudt: (impliciete) wetenschappelijke kennis beschikbaar maken voor computers, zodat dit nieuwe inzichten oplevert, en voor wetenschappers nieuwe aanknopingspunten voor onderzoek geeft. Onlangs begon Stork aan een nieuwe functie als universitair docent data science bij het INDElab van UvA’s Informatica Instituut, waar ze dit onderzoek voortzet. Daarbij wil ze zich op verschillende wetenschappelijke onderwerpen richten, zoals bijvoorbeeld sociale geschiedenis of biodiversiteit, onderwerpen die haar ook persoonlijk interesseren. ‘Ik heb de natuurlijke wereld altijd al heel fascinerend gevonden. Het voelt soms een beetje als een hobby om bezig te zijn met bijvoorbeeld geologie en dieren. En het is heel leuk om te zien hoe natuurhistorici werken. Ze zijn al veel bezig met het creëren van geavanceerde data-infrastructuren zodat data geïntegreerd en beter gebruikt kunnen worden.’ Door biodiversiteitskennis machine-leesbaar te maken, kunnen conclusies worden getrokken die ook voor andere velden interessant zijn, zoals klimaatstudies. ‘Ook de sociale geschiedenis is erg interessant, omdat studievariabelen daar vaak sociale constructies zijn. Hoe definieer je wat een beroep is, en hoe is dat gerelateerd aan sociale status? Onderzoekers van het Internationaal Instituut van Sociale Geschiedenis, waar ik mee samenwerk, zijn al bezig om dat in computer-leesbare taal te omschrijven.’
Veldboeken
Geschiedenis is bij uitstek een vakgebied waarin contextuele kennis erg belangrijk is. Dat ontdekte Stork al toen ze promotieonderzoek naar dit onderwerp in samenwerking met museum Naturalis in Leiden deed. Haar doel was toen om computers relaties te laten begrijpen tussen diverse, multimodale bronnen. Denk aan historische veldboeken, waarin dierbeschrijvingen bij expedities werden genoteerd. ‘Een onderzoeker die bijvoorbeeld in de negentiende eeuw naar Indonesië ging, noteerde in zijn veldboek: ik heb vandaag deze vleermuis gevonden. Door meta-informatie over die veldboeken machine-leesbaar te maken, kunnen koppelingen tussen multimodale bronnen gemaakt worden en krijgt zo’n veldboek weer context. Wie heeft het geschreven? In welke periode? Waar was diegene? Waren lokale mensen betrokken bij de zoektocht?’
Als we wetenschappelijke kennis meer machine actionable maken, dan bieden we onderzoekers de mogelijkheid om voort te kunnen bouwen op bestaande kennis.Lise Stork
Het werk van Stork gaat verder dan het digitaliseren van informatie. ‘Er wordt vaak veel tijd en moeite gestopt in het digitaliseren van de inhoud van bijvoorbeeld zo’n veldboek. Maar de eerste stap is eigenlijk dat je het online zet met de meta-informatie erbij. Mensen kunnen dan zelf met de inhoud aan de slag en verbanden leggen.’
Knowledge engineering
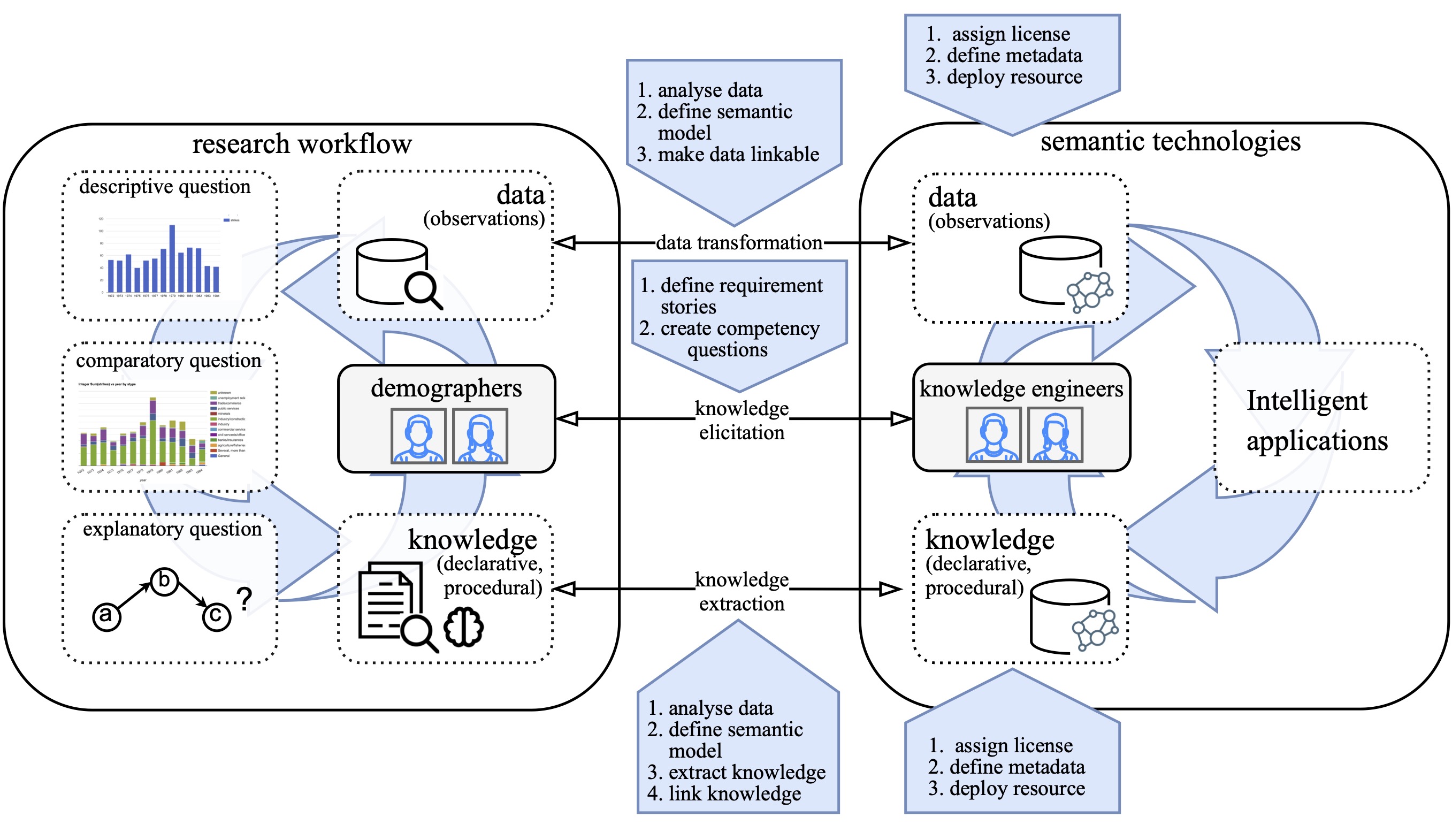
Bij haar onderzoek aan de UvA wil Stork onderzoeken wat de beste manieren zijn om (stilzwijgende) kennis van vakgebieden (domeinen) te vergaren, bijvoorbeeld van domeinexperts of kennis die is opgeschreven in teksten. Dit veld wordt ook wel knowledge engineering genoemd. Kennis wordt daarbij omgezet in een taal die een computer begrijpt, en kan dan gebruikt worden voor wetenschappelijke taken.
Dat wil ze samen gaan doen met een aantal promovendi, maar ook met experts van verschillende wetenschappelijke domeinen. Het onderzoek begint met literatuuranalyse: hoe werken knowledge engineers nu al samen met domeinexperts, en wat zijn de knelpunten? Stork wil ook specifiek kijken naar communityplatforms waarop wetenschappers samenwerken, zoals Githubs, blogs en wiki’s. Daar wil ze achterhalen hoe de data pipeline, oftewel het hele proces vanaf het inscannen van bronnen, het annoteren en het bouwen van een datamodel tot aan de analyse, in zijn werk gaat. ‘Daarnaast wil ik ook graag onderzoeken of delen van dit proces geautomatiseerd kunnen worden, bijvoorbeeld met behulp van AI-gebaseerde taalmodellen.’
Een belangrijke gids voor haar onderzoek is het FAIR-raamwerk. FAIR is een initiatief om data beter vindbaar, toegankelijk, interoperabel en herbruikbaar te maken. ‘Als we wetenschappelijke kennis meer machine actionable maken, dan bieden we onderzoekers de mogelijkheid om voort te kunnen bouwen op bestaande kennis.’
Informatie over INDELab